Optimized Inference at the Edge with Intel Workshop
I attended the Optimized Inference at the Edge with Intel workshop on August 9, 2018 at the Plug and Play Tech Center in Sunnyvale, CA. It was a one-day, hands-on workshop on computer vision workflows using the latest Intel technologies and toolkits. The main focus of the workshop was Intel’s Open Visual Inference & Neural Network Optimization (OpenVINO) toolkit. The goal is to learn how to optimize and improve performance with and without external accelerators, as well as utilize tools to help identify the best hardware configuration for your needs.
Workshop Format and Agenda

The workshop was led by Priyanka Bagade, IoT Developer Evangelist at Intel. The content for the workshop, including presentations and labs, is available on Intel’s Smart Video Workshop GitHub. A Lenovo laptop was provided for the workshop, along with a Movidius Neural Compute Stick. The laptop was running Ubuntu 16.04 and came preinstalled with all the workshop content (setup instructions are included in the README).

The agenda for the workshop was as follows:
- Intel Smart Video/Computer vision Tools Overview [slides]
- Basic End to End Object Detection Example [slides] [lab]
- Performance Gain with Hardware Heterogeneity [lab]
- HW Acceleration with Intel Movidius Neural Compute Stick (NCS) [lab]
- FPGA Inference Accelerator [slides]
- Optimization Tools and Techniques [slides] [lab] [lab]
- Advanced Video Analytics [lab] [lab]
Overview
The focus of the workshop was accelerating deep learning inferencing using Intel technologies. Mostly this pertained to utilizing OpenVINO to optimize pre-trained networks and run them on different Intel hardware, including CPU, GPU, FPGA and VPU. We were mainly looking at convolution neural networks for images and videos.
Inferencing
Inference is the action of applying a trained neural network to an input to generate an output. For example, let us say you have a network trained to identify dogs vs. cats in an image. You now want to use this network on a new image to see if the network predicts the image contains a dog or a cat. In fact, you want to deploy this network an a cloud server to detect dogs or cats in millions of user images. This is inferencing.
Inferencing is much less computationally intensive as compared with training. However, if you are running millions of inferences (as in the dog vs. cat service example), or you are running inferences on a constrained device (such as a Raspberry Pi), you may need acceleration to achieve the performance you desire. The performance criteria may include speed or power efficiency or both.
OpenVINO Toolkit
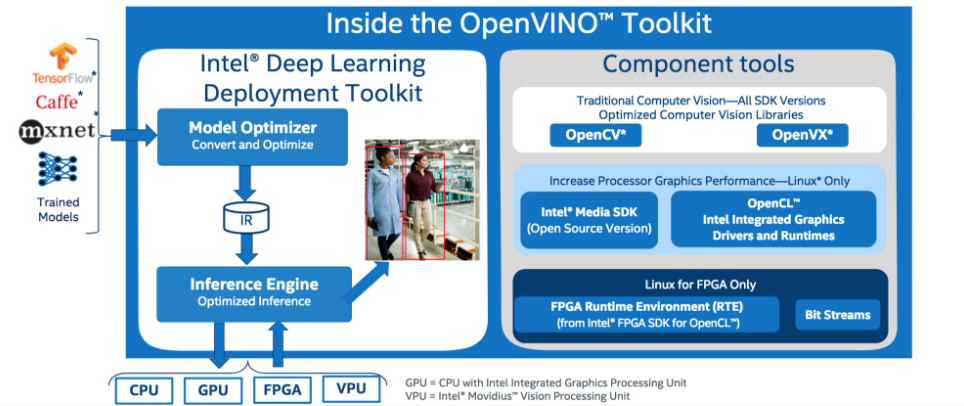
The OpenVINO Toolkit is an (mostly) open source toolkit from Intel. It works with pre-trained models in Caffe, TensorFlow or MXNet formats. The Model Optimizer converts the model into an intermediate format and performs some basic optimizations. The Inference Engine can then run the network on Intel CPUs, GPUs, FPGAs or VPUs (Movidius NCS). OpenVINO also contains tools for pre-processing and post-processing data which can be accelerated on CPUs or GPUs.
It is worth noting that OpenVINO uses a highly optimized library for CPU execution. So utilizing OpenVINO on your model will still provide performance improvements over running them through with Caffe, TensorFlow or MXNet on the same CPU.
Object Detection

The object detection section of the workshop walks through the development flow using OpenVINO for an object detection application. It also dives a little deeper into the main components of OpenVINO: Model Optimizer and Inference Engine.
Model Optimizer
The Model Optimizer reads in a model from one of the supported frameworks. It converts the model to a unified model intermediate representation (IR). The network is captured in an XML file and the weights are stored in a BIN file. The Model Optimizer also optimizes the model by merging nodes, decomposing batch normalization and performing horizontal fusion (essentially eliminating function call overhead). It will also perform quantization to convert from the input format (usually FP32) to the target format (FP16, INT8) as needed. Intel have already validated more than 100 commonly used models.
Note: The Model Optimizer does not support every known layer type. For a list of supported layers and information on supporting custom layers, check the Model Optimizer Guide.
Inference Engine
The Inference Engine is a unified API for inference across all Intel architectures. It provides optimized inference on Intel architecture hardware targets (CPU/GPU/FPGA/VPU). It provides heterogeneous support allowing execution of model layers across hardware types. It enables asynchronous execution to improve end to end performance. It provides a common framework for running inference on current and future Intel architectures.
Inference Engine APIs are supported in C++ and python. The basic workflow is
- Initialization
- Load model and weights
- Set batch size (if needed)
- Load inference plugin(s)
- Load model to plugin(s)
- Allocate input and output buffers
- Main Loop
- Fill input buffer with data
- Run inference
- Interpret output results
Note: The Inference Engine supports different layers for different hardware targets. For a list of supported devices and layers, check the Inference Engine Guide
Lab: Basic End to End Object Detection Example
The lab instructions are provided in the repository as Object detection with OpenVINO™ toolkit. The lab uses a Caffe implementation of the MobileNet SSD model. Run the Model Optimizer (mo_caffe.py) to generate the IR.
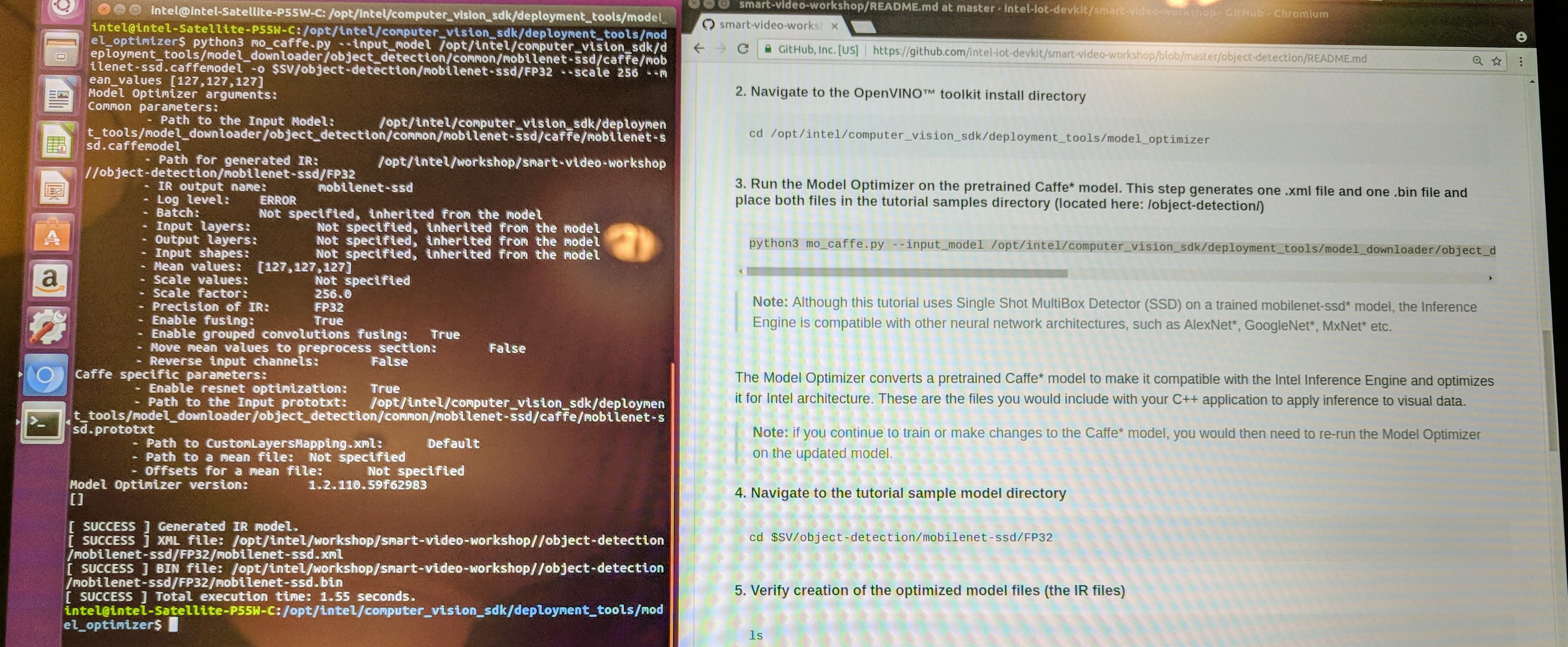
A sample application for the Inference Engine is provided as main.cpp. It will feed a video to the inference engine and outputs the results. This sample follows the basic workflow described earlier. For example, the code to load the model and weights is provided as
CNNNetReader network_reader;
network_reader.ReadNetwork(FLAGS_m);
network_reader.ReadWeights(FLAGS_m.substr(0, FLAGS_m.size() - 4) + ".bin");
network_reader.getNetwork().setBatchSize(1);
CNNNetwork network = network_reader.getNetwork();
Compile the application to tutorial1 and download a test video. Run the application on the CPU (by default).
./tutorial1 -i $SV/object-detection/Cars\ -\ 1900.mp4 -m $SV/object-detection/mobilenet-ssd/FP32/mobilenet-ssd.xml
Review the results with ROIviewer:
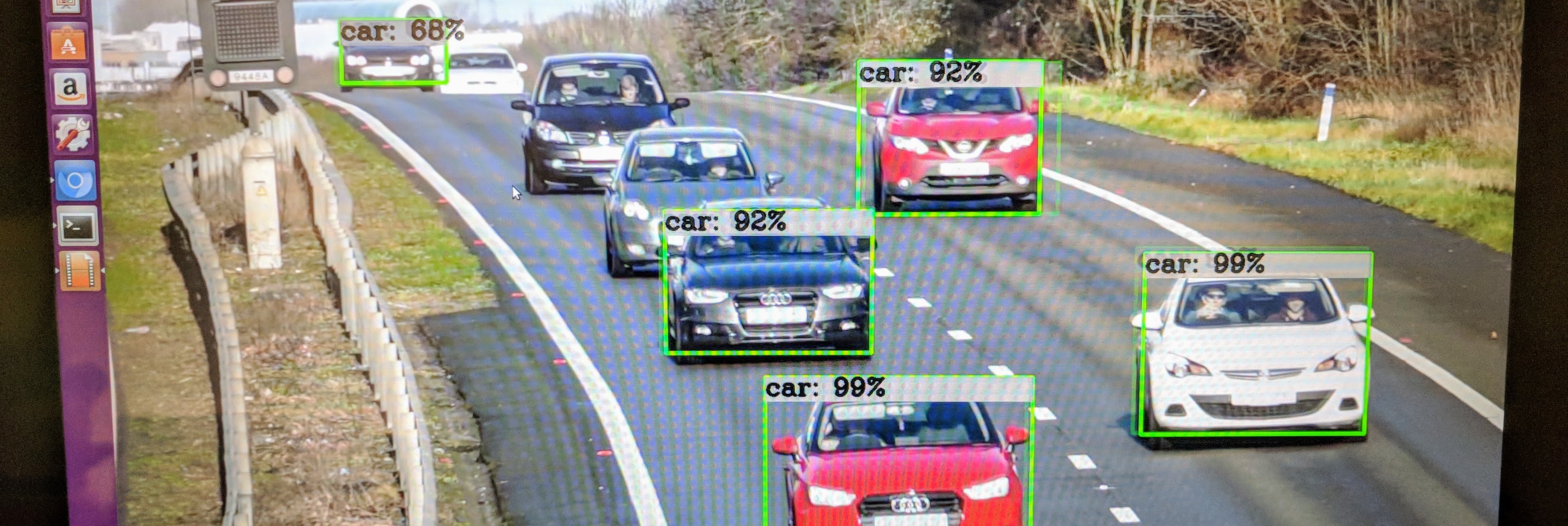
The sample application includes a flag to set the target device(s) and will load the appropriate inference plugin. We can run the application using the CPU:
./tutorial1 -i $SV/object-detection/Cars\ -\ 1900.mp4 -m $SV/object-detection/mobilenet-ssd/FP32/mobilenet-ssd.xml -d CPU
and the GPU:
./tutorial1 -i $SV/object-detection/Cars\ -\ 1900.mp4 -m $SV/object-detection/mobilenet-ssd/FP32/mobilenet-ssd.xml -d GPU
and compare the results:
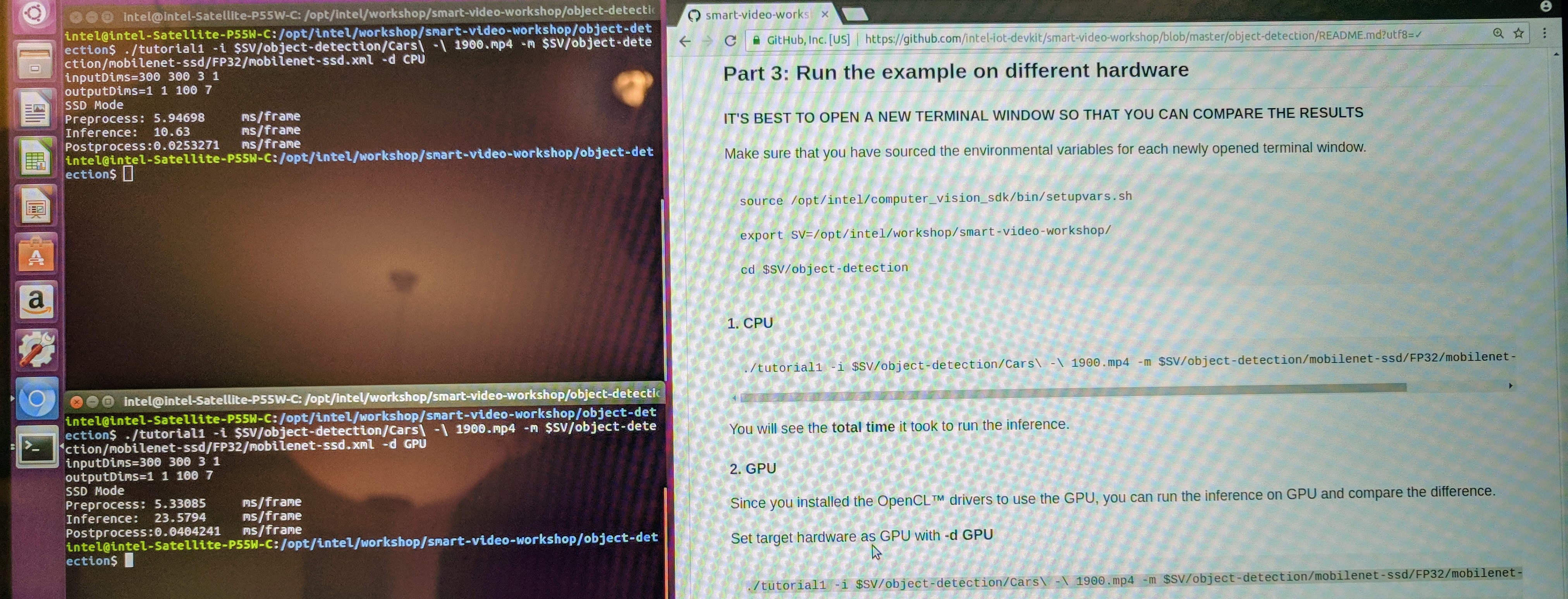
- CPU Inference Time: 10.63 ms/frame
- GPU Inference Time: 23.58 ms/frame
At first I was surprised to see that the GPU was quite a bit slower than the CPU. Then I realized that the on chip GPU (HD Graphics 530) is fairly wimpy compared to the 8-core Core i7-6700HQ.
Hardware Heterogeneity
OpenVINO enables running networks on heterogeneous hardware. One of the main reasons for heterogeneous support in OpenVINO is for fallback. If the high performance hardware doesn’t support all the layers in your model (e. g. FPGA), then you can run the layers it does support on the fast hardware, and run unsupported layers on other targets (e. g. CPU or GPU).
The sample application supports a HETERO device, which then allows you to prioritize the main device and a fallback device. For the lab, we used the CPU and GPU, and tried with each one as the main device. For example, here’s how we ran with the GPU as the prioritized device:
./tutorial1 -i $SV/object-detection/Cars\ -\ 1900.mp4 -m $SV/object-detection/mobilenet-ssd/FP32/mobilenet-ssd.xml -d HETERO:GPU,CPU
Since all the layers in the model are supported on both devices, the performance of each was about the same as if we ran with only that device:
- CPU/GPU Inference Time: 10.83 ms/frame
- GPU/CPU Inference Time: 23.42 ms/frame
OpenVINO provides additional examples of the Inference Engine APIs. These examples include a -pc flag, which shows performance on a per layer basis. The lab runs through such an example with a car image classifier using SqueezeNet.
Hardware Acceleration with NCS
The next section of the workshop utilizes the Intel Movidius Neural Compute Stick (NCS). The NCS is a neural network accelerator in a USB stick form factor. It features the Movidius Vision Processing Unit, Myriad 2. The VPU solutions are intended for edge applications where compute power is limited and low-power is required. Example applications include drones, surveillance camera and virtual reality (VR) headsets.
For the lab, we can run the same sample program, tutorial1, with the device flag set to MYRIAD:
./tutorial1 -i $SV/object-detection/Cars\ -\ 1900.mp4 -m $SV/object-detection/mobilenet-ssd/FP32/mobilenet-ssd.xml -d MYRIAD
The NCS only supports FP16, and so far we have only used FP32. We need to run the Model Optimizer to quantize the model using --data_type FP16:
python3 mo_caffe.py --input_model /opt/intel/computer_vision_sdk/deployment_tools/model_downloader/object_detection/common/mobilenet-ssd/caffe/mobilenet-ssd.caffemodel -o $SV/object-detection/mobilenet-ssd/FP16 --scale 256 --mean_values [127,127,127] --data_type FP16
The inference time is slower than the GPU and CPU:
- MYRIAD Inference Time: 82.74 ms/frame
FPGA Inference Accelerator
Field-Programmable Gate Arrays (FPGAs) are a type of integrated circuit which can be configured after manufacturing. They consist of an array of programmable logic blocks, memory and reconfigurable interconnects. They can be programmed in the field to support any number of applications. Because they are programmable, they can be configured to support the exact acceleration necessary to support a specific neural network. Normally this requires extensive hardware development expertise, but OpenVINO aims to address some key challenges:

OpenVINO includes bitstream libraries, which are precompiled FPGA images for specific models. Custom bitstreams can be created using FPGA development tools. Bitstreams are loaded into the FPGA as part of the inference model for the device. Now the FPGA can be utilized as a target just like the others. Currently, OpenVINO has limited support for FPGA devices and network layers. See the Model Optimizer Guide for details. The HETERO plugin is pretty much mandatory to provide fallback support to the CPU and/or GPU.
Optimization Tools and Techniques
There are a number of optimization tools and techniques available. For example, the Model Optimizer can perform some basic optimization as previously mentioned. You can utilize the Model Optimizer and Inference Engine to run multiple models on multiple targets to find the best combination for your needs. You can utilize the performance counter APIs to get layer by layer performance numbers. You can utilize batching and asynchronous APIs to improve throughput. Increasing the batch size on tutorial1 provides some performance benefit:
- Batch Size 01: 10.65 ms/frame
- Batch Size 02: 09.96 ms/frame
- Batch Size 08: 09.37 ms/frame
- Batch Size 16: 09.47 ms/frame
By the time we get to a batch size of 16, the performance starts to decrease, likely due to reaching compute and/or memory constraints.
You may be able to trade of a little precision for better performance by quantizing the model, for example the GPU runs faster at FP16 than at FP32 with little impact on accuracy.
VTune Amplifier
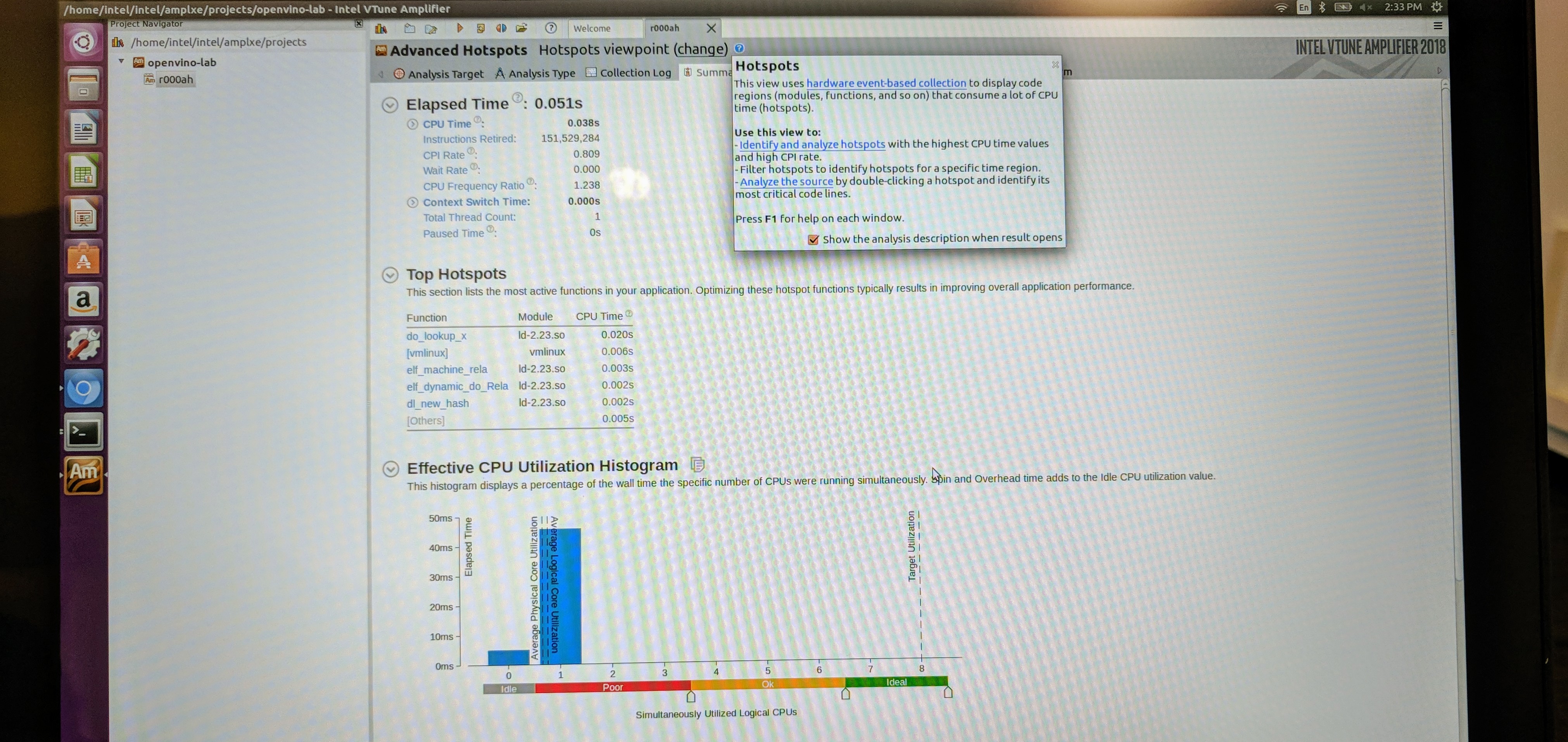
VTune Amplifier is a performance profiler from Intel. It has heterogeneous capabilities (CPU and GPU) and can be used with OpenVINO Inference Engine applications. The lab provided some hands on experience with VTune Amplifier using the same tutorial1 application.
We used the tool to analyze the timing data and top hotspots. The timing data includes things like CPU time, Clocks Per Instruction (CPI) rate and context switch time. The tool also listed the top 5 functions and top 5 tasks by CPU time as well as the effective CPU utilization histogram (cores and threads). A bottom-up view shows a sortable list of all functions. It includes an execution timeline which provides some insight into task switching an thread stalls.
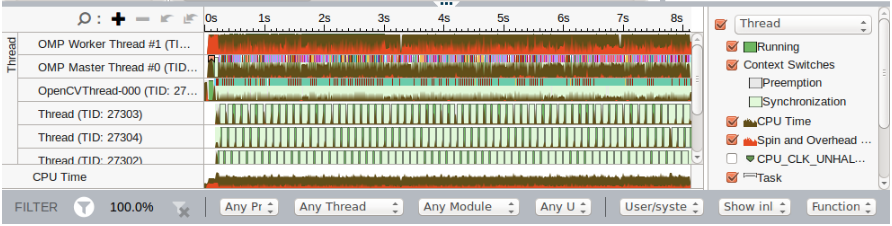
To complete the lab, we reran the application using different parameters to see how they affect the timeline. We also used the tool to compare two different runs.
Advanced Video Analytics
In the final section of the workshop we looked into some advanced topics such as chaining models and running multiple models on different hardware. We also ran through a TensorFlow example.
Chaining Models
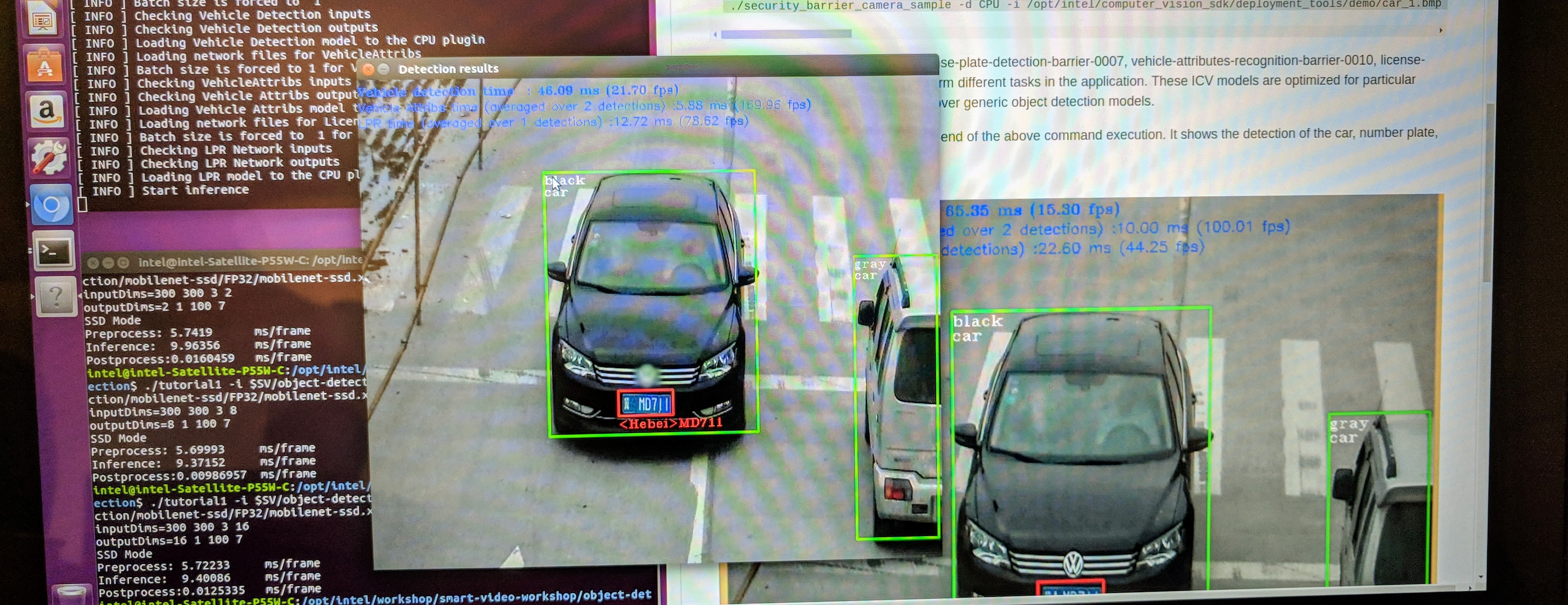
For this exercise we used the security barrier example included with the OpenVINO toolkit. This example uses 3 models to detect cars, their number plates, color and number plate attributes from the input video or image of the cars. The Intel models included in the application are:
- vehicle-license-plate-detection-barrier-0007: detects cars and license plates
- vehicle-attributes-recognition-barrier-0010: classifies car type and color
- license-plate-recognition-barrier-0001: recognizes Chinese license plates
There are a number of pre-trained models provided with the OpenVINO toolkit. Running the example application with a car image produced this result:
Multiple Models on Multiple Hardware
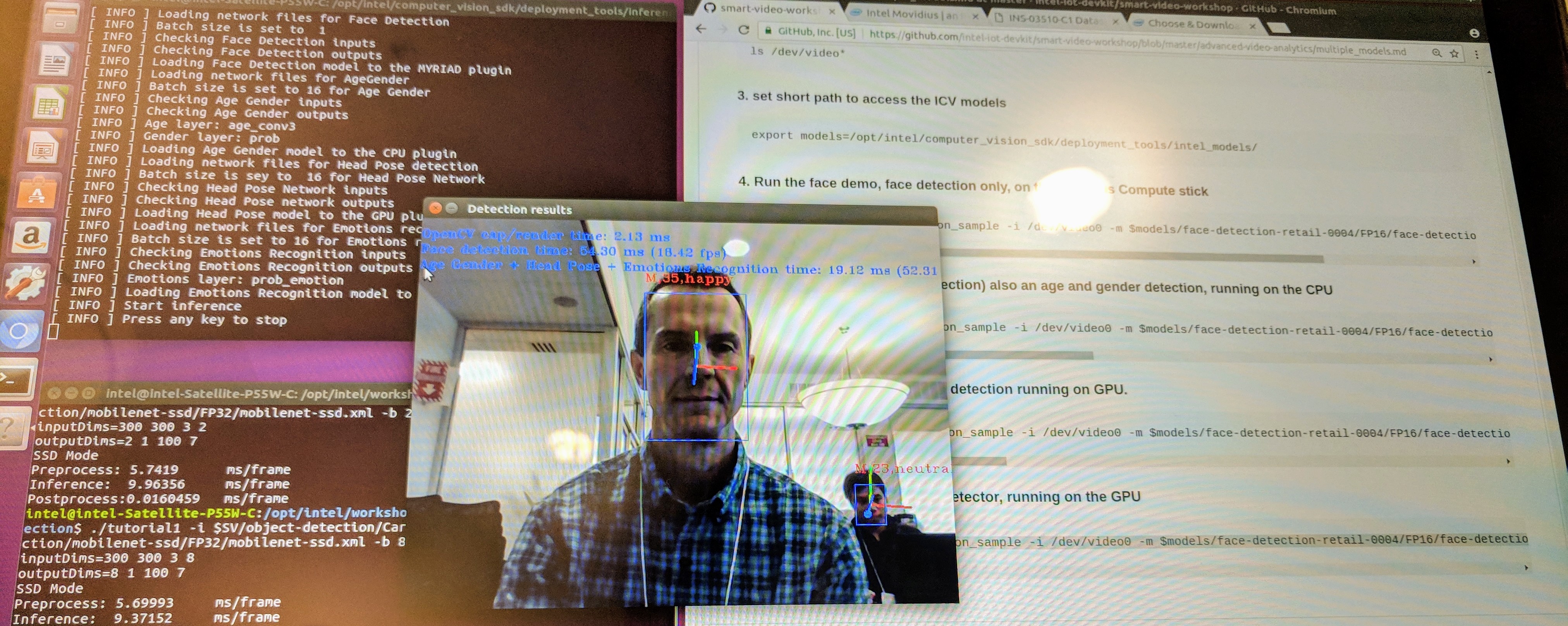
For this exercise we used the face detection example included with the OpenVINO toolkit. This example application can utilize models for face detection, age and gender detection, head pose estimation and emotion detection. We can also assign each model to run on different hardware. We ran the following models on the specified hardware:
- face-detection-retail-0004.xml: MYRIAD
- age-gender-recognition-retail-0013.xml: CPU
- head-pose-estimation-adas-0001.xml: GPU
- emotions-recognition-retail-0003.xml: GPU
with the built in camera, /dev/video0, as the input using this command:
./interactive_face_detection_sample -i /dev/video0 \
-m $models/face-detection-retail-0004/FP16/face-detection-retail-0004.xml -d MYRIAD \
-m_ag $models/age-gender-recognition-retail-0013/FP32/age-gender-recognition-retail-0013.xml -d_ag CPU \
-m_hp $models/head-pose-estimation-adas-0001/FP16/head-pose-estimation-adas-0001.xml -d_hp GPU \
-m_em $models/emotions-recognition-retail-0003/FP16/emotions-recognition-retail-0003.xml -d_em GPU
The application output the video stream with all the model annotations like this:
TensorFlow
The final exercise of the day was to run through an example using a TensorFlow model. The laptops already had the TensorFlow framework installed. We cloned the TensorFlow model repository and used an inception_v1 model. There are a few steps to setting up the TensorFlow model before running the Model Optimizer. Once we have completed these steps and run mo_tf.py, we have the OpenVINO IR model. A sample application, classification_sample, was provided. Once we have all the pieces in place, we ran:
./classification_sample -i car_1.bmp -m inception_v1_frozen.xml
The sample application utilizes the Inference Engine to run the model. The output is the top 10 results of the classifier for an input image.
Final Thoughts
I enjoyed the workshop. Priyanka did a great job presenting the OpenVINO material, and handed off to other Intel colleagues for presentations on FPGA and VTune Amplifier. There were a few other Intel employees on hand to assist with the labs. The labs were pretty easy since everything was set up and it’s pretty much cut and paste, but it still provided a pretty good overview of how and why you might want to use OpenVINO.
Conceptually, OpenVINO is a great toolkit for deploying deep learning inference. Having a common framework that can combine models from different frameworks and run them on different hardware is compelling. The obvious limitation is lack of support for non-Intel architectures. Since the toolkit is meant to be open source, perhaps other vendors will add in support for their architectures. It would be great to see support for NVIDIA, AMD, Arm and others. In the meantime, I may try it out on an Intel Atom board with the Movidius NCS.
VTune Amplifier is also a very powerful tool. It looks especially useful for deploying on Intel CPUs. Maybe I will try it with the Atom board as well.
Keep an eye out for this workshop. It’s worth a go if it comes near you. You can always work through the workshop content on your own, but that won’t get you any of the free give-a-ways!
