First Kaggle Competition
In addition to the BearID project, we have been learning about neural networks and machine learning through online courses, videos, blogs, etc. To help cement some of the concepts we learn, we need to apply them. In one of the online courses fast.ai’s Practical Deep Learning For Coders, Part 1, we were introduced to Kaggle.
Among other things, Kaggle is a platform which hosts data science and machine learning contests. The fast.ai course recommends these contests as a way to apply what you are learning. In fact, one of the first lessons walks through the use of a pre-trained neural network to create a submission for the Dogs vs. Cats playground competition (playground competitions have no point or cash awards). After applying our knowledge to a few playground competitions, we tried our had at a “real” competition: the Statoil/C-CORE Iceberg Classifier Challenge.
The Competition
Ship or iceberg, can you decide from space?
The goal of this contest was to take some snippets of remote sensing data and determine if the object in the data is a ship or an iceberg. The dataset consisted of satellite RADAR images and the incidence angle at which they were captured. The RADAR images included 2 channels of 75x75 pixel information with different polarizations. The training set contained labels indicating if the image contained a boat or an iceberg. The results would be scored across a test set using logarithmic loss (the lower the log loss the better).
The Networks
After some initial research into RADAR imaging and incidence angles, we we not able to find a satisfactory formula to apply to the data to transform it into something more useful. Instead, we decided to approach the problem as if the 2 channels were like 2 of the 3 channels of a typical RGB image.
Vggish
Previously, we had learned about a commonly used Convolutional Neural Network (CNN) called VGG. VGG expected an RGB image, and we only had 2 channels. So we started out by building a stripped down version of VGG with an input of 75x75x2 channels and trained it from scratch. Our network had 3 layers of convolution and pooling followed by 2 fully connected layers and finally a sigmoid classifier. After tuning a few hyperparameters and adding some data augmentation, we achieved a log loss score of 0.2509.
Fully Convolutional Network
In the fast.ai course we learned about the Fully Convolutional Network (FCN). In an FCN, there are no fully connected layers. Essentially you to continue to convolve and pool until you have a fairly small image. In your final convolution, you end up with the same number of channels you want to classify (in our case, 2). We used 5 layers of convolution followed by a softmax classifier. An interesting side effect of this network is that you can use the final layers to create a heat map of the “ship-ness” or “berg-ness” of an image. Here’s an example heat map which has been overlaid on the original image:
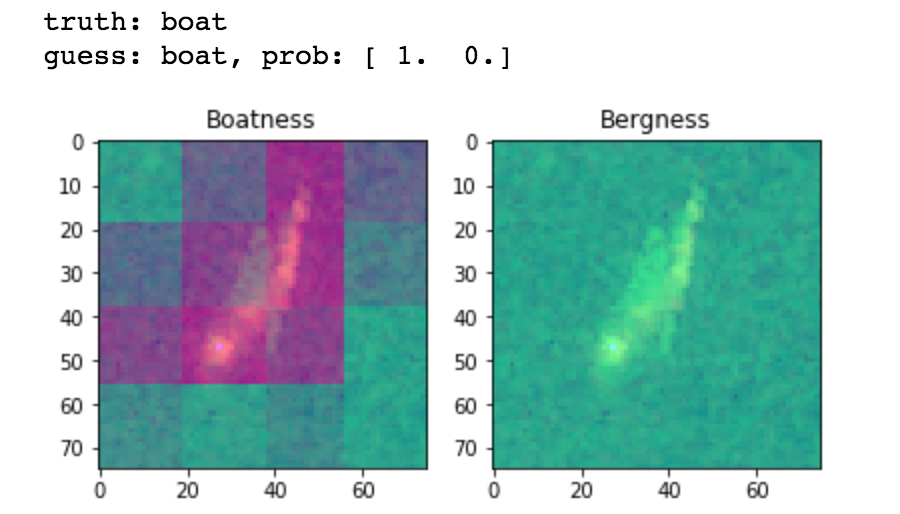
I wrote a Kaggle Kernel to share this architecture. Our best score with the FCN was 0.1931.
Pre-trained Networks
There are a number of network architectures which have already been trained for image based object detection. We decided to give a few of these a try, namely: ResNet, DenseNet and VGG. To use the pre-trained models, we had to create a third data channel, which we did simply by averaging the other 2. We also had to upscale the images from 75x75 to 224x224 (or similar, depending on the network).
For ResNet, we used the bottleneck features (the output from all the convolutions) and trained a couple fully connected layers from scratch. This didn’t give us a very good score on our local validation set, so we never submitted it to Kaggle.
For VGG and DenseNet, we fine-tuned all the layers using our augmented training data. This gave us better results. Our best DenseNet score was 0.1856 and our best VGG score was 0.1521. At the time, the VGG score put us in the top 50, but that didn’t last long.
VGG + Incidence Angle
Finally, we decided we needed to figure out how to use the incidence angle. We started with the VGG model and concatenated in the incidence angle with the results of the final convolution and flatten, which then fed into the folly connected layers. Our best result with this method was a little worse than VGG alone, coming in at 0.1679.
Ensembles
We already knew about ensembles, which is a concept of combining multiple models to achieve better results. We were using a simple version of this with many of our networks. We were splitting our data into 4 subsets (folds) and training 4 different models on each combination of 3 folds for training and one for validation. We would run predictions for the test data on each model and average them. We did this for many of the models above.
Near the end of the competition, we realized we needed to combine our best models to achieve a lower score. After reading some posts, we learned about using a MinMax method combined with Median. The MinMax idea is that if all of your models agree (above or below some threshold), then you should use the Min or Max of those models (depending on if they agree towards 0 or 1). For the cases where the models don’t agree, use the Median (this works better than the Mean, especially when most of your models agree).
We decided to combine 5 models. To have some variation, we used our best scoring models of Vggish, FCN, VGG and VGG + Incidence Angle (we didn’t have a good result for DenseNet yet). For a fifth model, we used our second highest scoring VGG model (0.1674). This ensemble scored 0.1458.
Results
With our score of 0.1458, we finished 733 of 3343 teams on the public leader board. However, the public leaderboard uses only 20% of the test results. The final scoring, the private leader board, uses the other 80% and is only published after the competition ends.
On the private leaderboard, we only scored 0.1566, but we finished 486 of 3343. That put us in the top 15%. Still not good enough for points or a prize, but not too bad.

We had a couple other networks we had trained at the last minute, but we weren’t able to submit (you can only make 2 submissions per day). We have since submitted them just to see the results. We had a DenseNet model that scored 0.1856 and another VGG model (with different augmentation options) which scored 0.1603. It turns out, if we had used the DensNet instead of Vggish and newer VGG instead of our previous 2nd best VGG, our ensemble public score would have been 0.1428 and the private score would have been 0.1491. That would have moved us up to 372 (top 12%), but still no points (for a competition this size, you need to be in the top 10% for a medal).
Lessons Learned
While we didn’t win anything in our first Kaggle competition, we did learn a few valuable lessons:
- Submit early and often! You only get 2 submissions per day. Don’t wait for the last minute! We only made 16 submissions during the 3 months of competition.
- Try more architectures, and try them more throughly. ResNet probably would have done better if we re-trained all the layers. There were a few other architectures we didn’t even get to.
- We have a lot to learn about ensembles, including bagging, boosting and stacking. We’ll be spending some time reading various posts on Kaggle from previous winners and the Kaggle Ensembling Guide.
Hopefully we’ll do even better on the next contest!