Bear Face Detector
In the last post, Find the Bears: dlib, we introduced Histogram of Oriented Gradients (HOG) and the dlib toolkit. We went through installing and building dlib on a Linux Virtual Machine, then ran through a HOG based face detection example. Now we will try to build a detector for bear faces using the dlib Train Object Detector command line tool example.
Labeling Data
The first thing we need to do is create a training set of annotated images. Basically, we need to gather a set of bear images and manually draw bounding boxes around each of the bears’ faces. Fortunately, the dlib toolkit includes a simple graphical tool for annotating images called imglab. In addition to enabling the annotation of bounding boxes, imglab also supports the labeling of object part locations. This will come in handy later when we need to identify landmarks for the object reorientation stage.
Building imglab is similar to building the main dlib toolbox (starting from the top dlib directory):
cd tools/imglab
mkdir build
cd build
cmake ..
cmake --build . --config Release
To use imglab, first create a XML file containing links to your test images. Do this by invoking the tool with the -c option, a target XML file name and the directory containing your images:
./imglab -c [target.xml] [image_dir]
This creates the XML file (e.g. target.xml) which contains a list of all the images in image_dir. To start labeling, run the tool again with only the XML file as a parameter:
./imglab [target.xml]
This will launch a window with a list of all the images and one image displayed. Use the arrow keys to cycle though the images and the mouse to label objects. Hold the shift key, left click and drag the mouse draw boxes around the objects you wish to detect. If there are objects which you are not sure about you should draw a box around them, then double click the box and press i. This will cross out the box and mark it as “ignore”. The training code in dlib will then simply ignore detections matching that box. Once you finish labeling objects in all the images, go to the file menu and click save. Your XML file (e. g. target.xml) will now contain bounding box information. You can invoke the tool in the same way to review or edit your annotations.
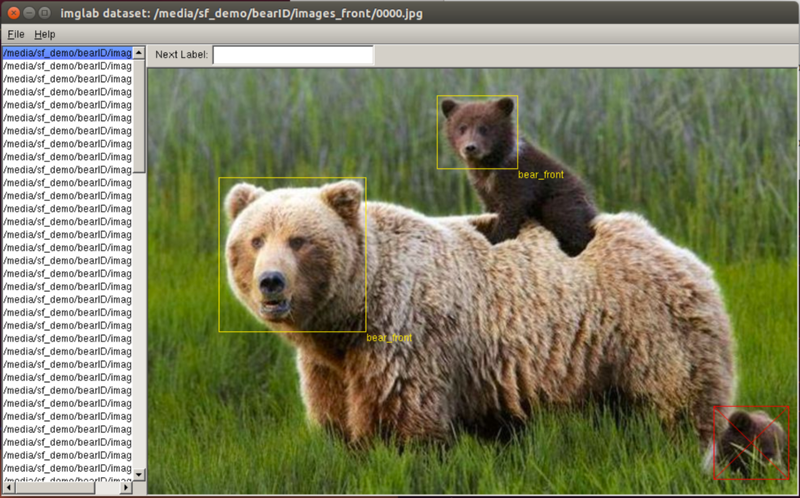
Above is a screen capture if imglab with annotations from our training set. Notice the example image has two bounding boxes and one ignore (since you can’t clearly see the third bear’s face). For now we are concentrating on images where the bears are looking roughly toward the camera. This will (hopefully) simplify our face encoding stage later on. As a start, we created a training set of 98 images containing a total of 117 labeled bear faces.
Training the Bear Face Detector
Now that we have a basic training set, we can start training our detector. The command line training tool, train_object_detector, should already be built in the /examples/build directory from last time. We simply need to run the training using the following command:
./train_object_detector -tv [target.xml]
 Our training ran for 102 iterations. The model is saved to the file object_detector.svm. The model is automatically tested on the training data. We got a precision of 1.00, but a recall of only 0.43. A visualization of the HOG model captured by this training can be seen in the image to the right. You will see the visualization when you run the detector. Our’s is pretty clearly a bear!
Our training ran for 102 iterations. The model is saved to the file object_detector.svm. The model is automatically tested on the training data. We got a precision of 1.00, but a recall of only 0.43. A visualization of the HOG model captured by this training can be seen in the image to the right. You will see the visualization when you run the detector. Our’s is pretty clearly a bear!
Detecting Bears
Once training is finished, we can use the object detector to locate objects in new images with a command like:
./train_object_detector some_image.png
This command will display some_image.png in a window and any detected objects will be indicated by a red box. Using our newly trained bear detector, we saw the following results on one of our training images (bear 128 Grazer):

Note that the image is black and white. The HOG method works on the change in intensity between pixels. It doesn’t really care about the color information. Both training and detection will first convert the image to black and white.
Next Steps
Our detector is basically working, but based on the recall number
true positives / (true positives + false negatives)
we have a lot of false negatives (where the bear face was not detected). We need to increase our training data and perhaps clean up our annotations. We have three ideas for our next step:
- Improve our training data and run through training variations (for example, the training tool can automatically scale and flip images to provide more training examples).
- Have a look at a CNN based object detector using dlib as described in this blog post.
- Park object detection for now, and move on to the other stages (reorienting, encoding and matching) to prove feasibility of the entire pipeline.
In addition to the above, we need to think about building a GPU based server. We will most likely need this for training CNN based models.
Tune in next time to see which way we go.