Find the Bears: YOLO
In the last post, FaceNet for Bears, we described a face recognition pipeline inspired by the article, Modern Face Recognition with Deep Learning. The first stage of the pipeline is “Find the Face”. In our case we need to train an object detector to find and locate bear faces in images. The goal is to be able to input an image to the detector and have it output the location (as a bounding box) of each bear face it detects.
Object detection is one of the main ImageNet Challenges. Bear is also one of the categories in the ImageNet Dataset (see screen capture above showing part of the bear dataset). As such, there are numerous networks trained to detect the entire bear. Our thought was to start with one of these networks and fine tune the detector to zero-in on bear faces.
Transfer Learning
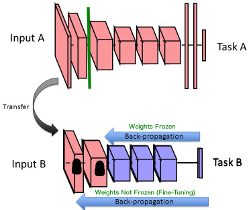 The approach we are planning makes use of a process called transfer learning. The idea is to start with a network which already does something similar to what we want, such as a CNN trained to detect objects (including bears), then retrain some number of the layers of the network using the specific training data for our needs (see image on right from Transfer Learning presentation). Generally speaking, the convolutional layers of a CNN learn lower level image features while the fully connected layers evaluate the features to determine what they describe. We would start with a pre-trained network and freeze the weights of the convolutional layers. Then we retrain the fully connected layers and classifiers using our bear faces training set. This should get us to a working model much more quickly than starting from scratch. Further refinements can be achieved by unfreezing the weights of the convolutional layers and performing additional training. This is called fine tuning.
The approach we are planning makes use of a process called transfer learning. The idea is to start with a network which already does something similar to what we want, such as a CNN trained to detect objects (including bears), then retrain some number of the layers of the network using the specific training data for our needs (see image on right from Transfer Learning presentation). Generally speaking, the convolutional layers of a CNN learn lower level image features while the fully connected layers evaluate the features to determine what they describe. We would start with a pre-trained network and freeze the weights of the convolutional layers. Then we retrain the fully connected layers and classifiers using our bear faces training set. This should get us to a working model much more quickly than starting from scratch. Further refinements can be achieved by unfreezing the weights of the convolutional layers and performing additional training. This is called fine tuning.
Bounding Box
 In addition to detecting the object, we need the network to identify where the object is within the image (see example on left from ILSVRC2014). This is typically accomplished by having the network output a bounding box for the object. We will use the bounding box to extract the bear face to pass to the next stage of our face recognition pipeline. The images used for training the network will need to include annotations which define the bounding boxes for the desired objects in each image. That means we will need to annotate quite a few images with bounding boxes for the bears’ faces.
In addition to detecting the object, we need the network to identify where the object is within the image (see example on left from ILSVRC2014). This is typically accomplished by having the network output a bounding box for the object. We will use the bounding box to extract the bear face to pass to the next stage of our face recognition pipeline. The images used for training the network will need to include annotations which define the bounding boxes for the desired objects in each image. That means we will need to annotate quite a few images with bounding boxes for the bears’ faces.
Region-based Convolutional Neural Network (R-CNN)
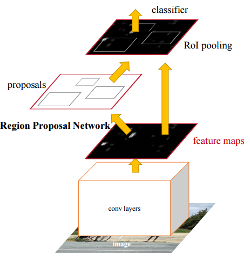 We can use the pre-trained convolutional layers as a sort of feature detector and retrain the fully connected layer and classifier to meet our identification needs. We need to add in a mechanism to define the bounding boxes. One method for for this is Region-based CNN (or R-CNN). R-CNN uses the CNN to define feature maps and adds a Region Proposal Network to to identify candidate regions of interest in the image (see diagram from Faster R-CNN). The classifier determines which, if any, objects are in the proposed regions. Regions with a high probability of containing objects are output with their classifications and bounding boxes. For increased accuracy, the input images are typically scaled to multiple resolutions (creating an image pyramid), each of which is run through the system.
We can use the pre-trained convolutional layers as a sort of feature detector and retrain the fully connected layer and classifier to meet our identification needs. We need to add in a mechanism to define the bounding boxes. One method for for this is Region-based CNN (or R-CNN). R-CNN uses the CNN to define feature maps and adds a Region Proposal Network to to identify candidate regions of interest in the image (see diagram from Faster R-CNN). The classifier determines which, if any, objects are in the proposed regions. Regions with a high probability of containing objects are output with their classifications and bounding boxes. For increased accuracy, the input images are typically scaled to multiple resolutions (creating an image pyramid), each of which is run through the system.
R-CNN has gone through a number of generations resulting in speed and accuracy improvements. A more recent version, Faster R-CNN, makes use of a pre-trained VGG16 which is a 16-layer CNN. You can find implementations of R-CNN variations in Matlab, Caffe, Torch and other languages and machine learning frameworks. Even with the use of transfer learning, these methods still require significant re-training to achieve the desired results. Since we currently don’t have access to GPU hardware and a large training set of bear faces, we wanted to get started with something a bit more light weight.
You Only Look Once (YOLO)
While searching for fast object detection, we ran across the YOLO: Real-Time Object Detection project. YOLO was developed on top of Darknet, an open source neural network package written in C. YOLO applies a single neural network, called Extraction (based on stripped down GoogLeNet) to the full image. It does not an image pyramid for the input image. The image is divided into regions and the network predicts bounding boxes and probabilities for each region. The bounding boxes are weighted by the predicted probabilities.

Trying the YOLO detector is a straightforward process. Following the Darknet Installation instructions, we cloned Darknet and built it on a Macbook Pro (without GPU support). The Darknet source tree already includes a number of models in the cfg/ directory, including their full YOLO network, yolo.cfg. They also provide the pre-trained weights files for some of the networks, such as yolo.weights. We were quickly able to run a detection on one of the included sample images using the following command:
./darknet detect cfg/yolo.cfg yolo.weights data/dog.jpg
Since bear is already a known object for YOLO, we could run the detector on one of our test images to get the following result:

Before attempting to retrain YOLO for bear faces, we wanted to understand the training process. We switched to their smaller Tiny YOLO detector, which uses the Darknet Reference Model (based on AlexNet). To take advantage of Transfer Learning, we downloaded the pre-trained weights for only the convolutional layers and locked those in. We tried running the training process for the rest of the network using existing training sets, but didn’t have any luck. The training just wasn’t converging. After raising an issue with the developer, we found out that CPU-only training (without GPU support) had not been tested, and portions of it were known to be broken.
Now What?
While CPU-only support for Darknet training may get fixed, it was clear that GPUs were needed to really pursue this path. Since we’re not quite ready to invest in a GPU platform at this point (though we will most likely have to eventually), we decided to seek other alternatives. Going back to the article that introduced us to the FaceNet pipeline, Modern Face Recognition with Deep Learning, we decided to check out the face detection method described there, Histogram of Oriented Gradients (HOG) using the dlib toolkit.
That will be the focus of the next blog.